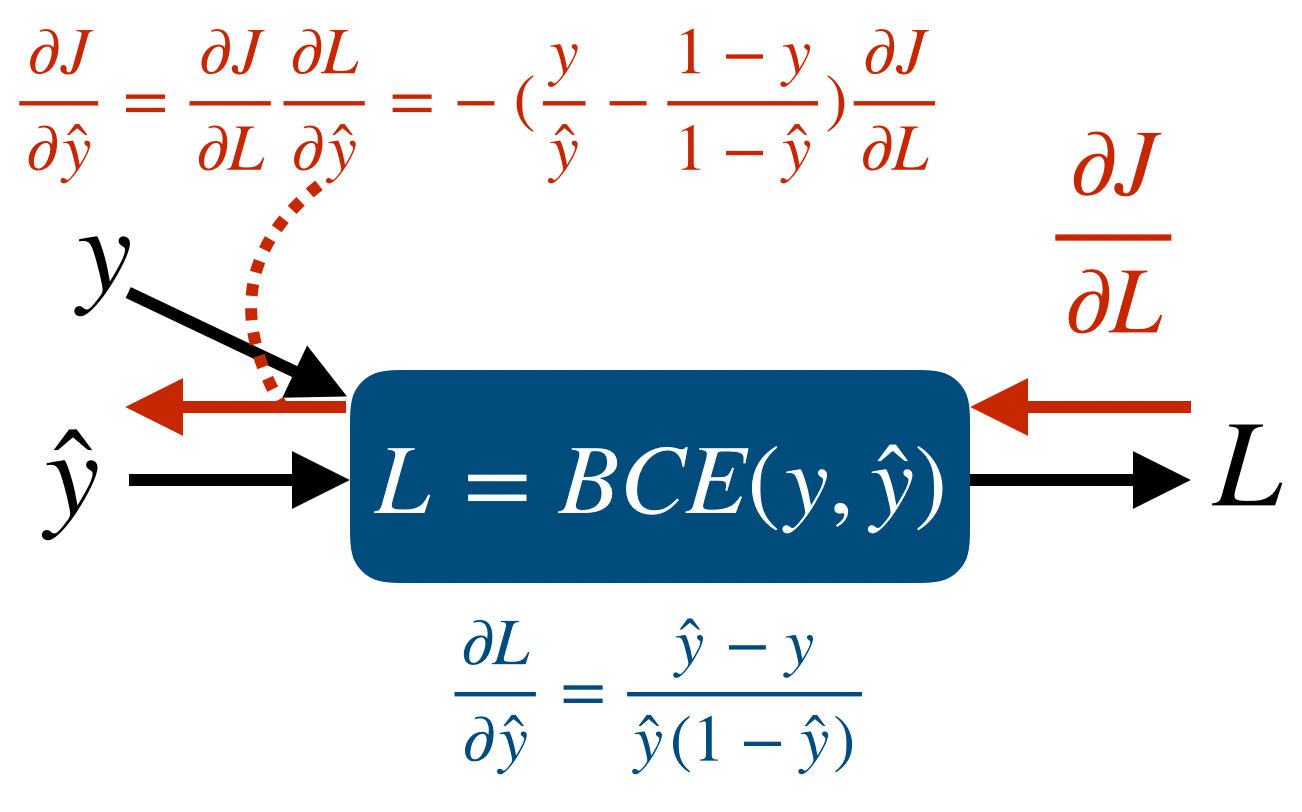
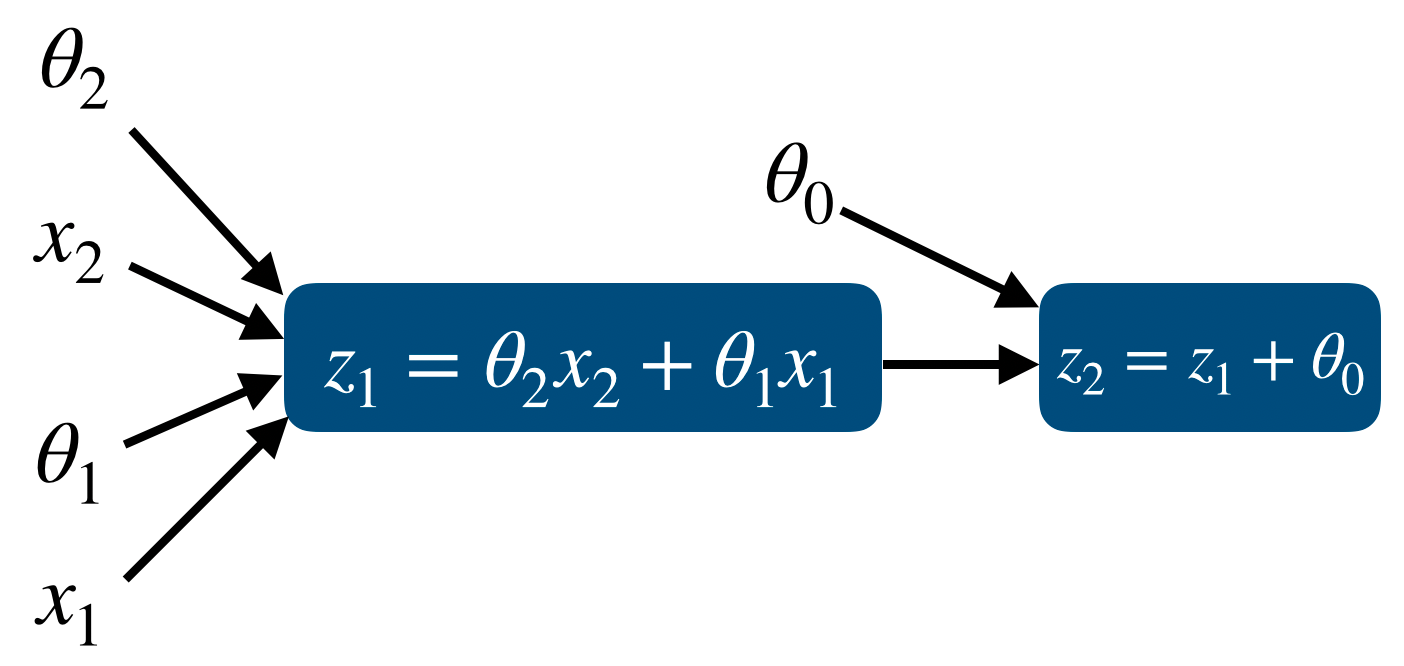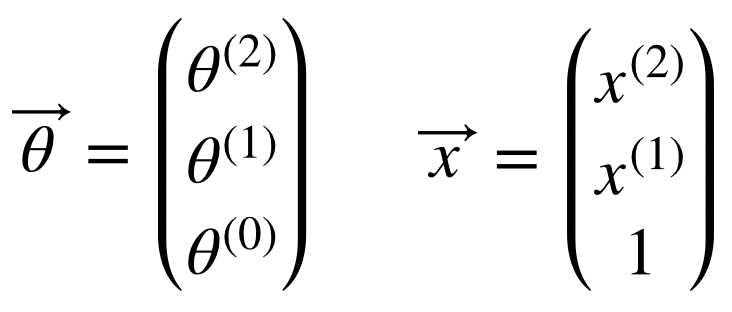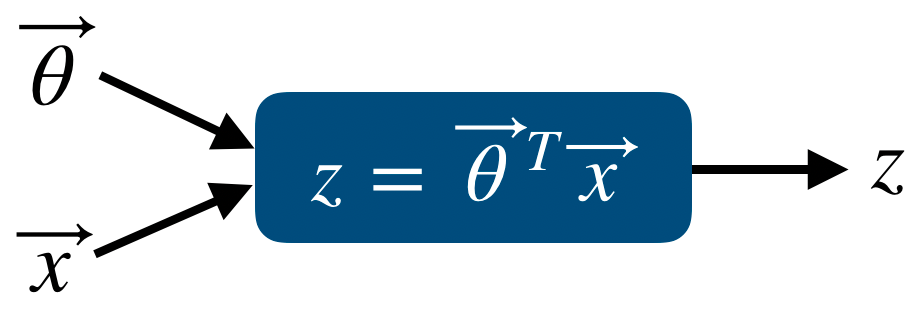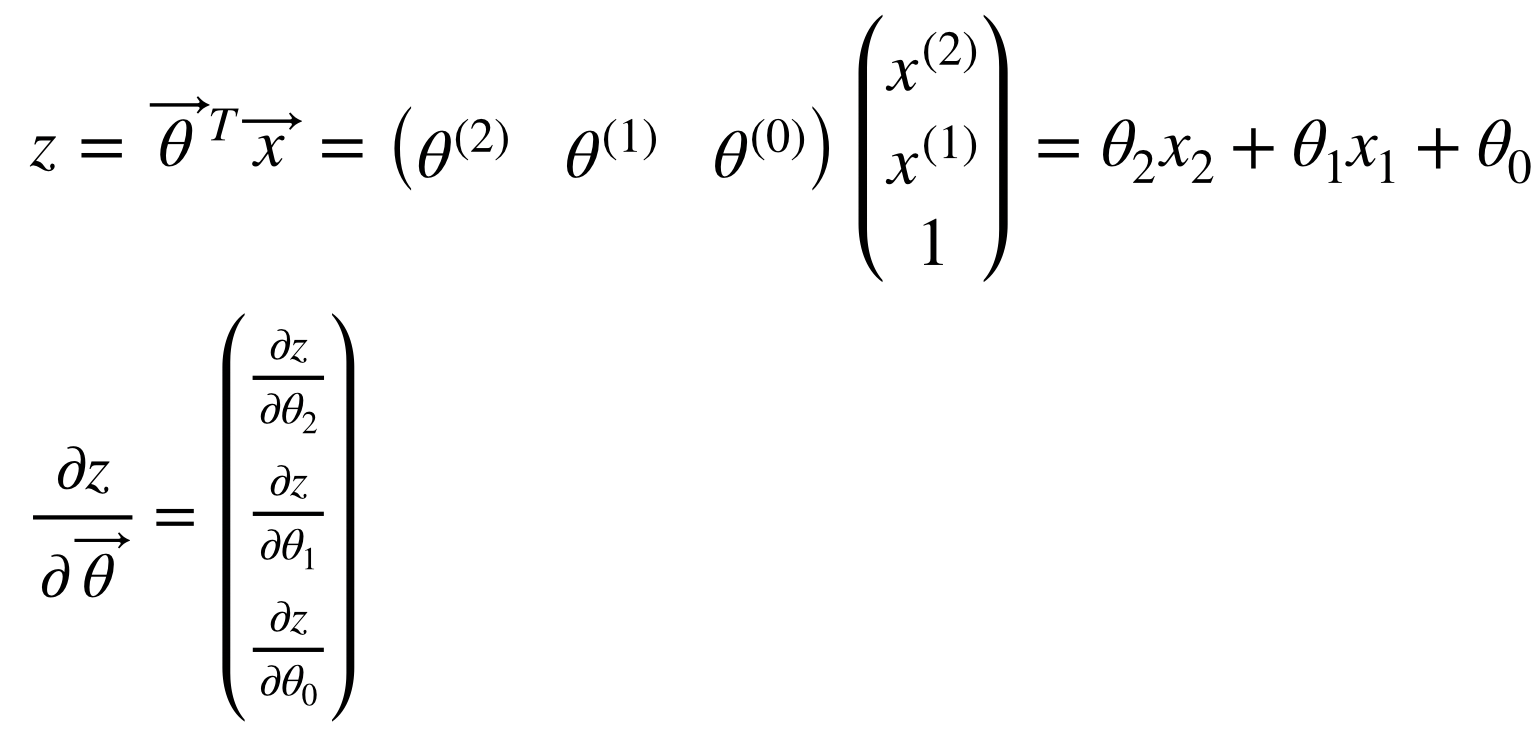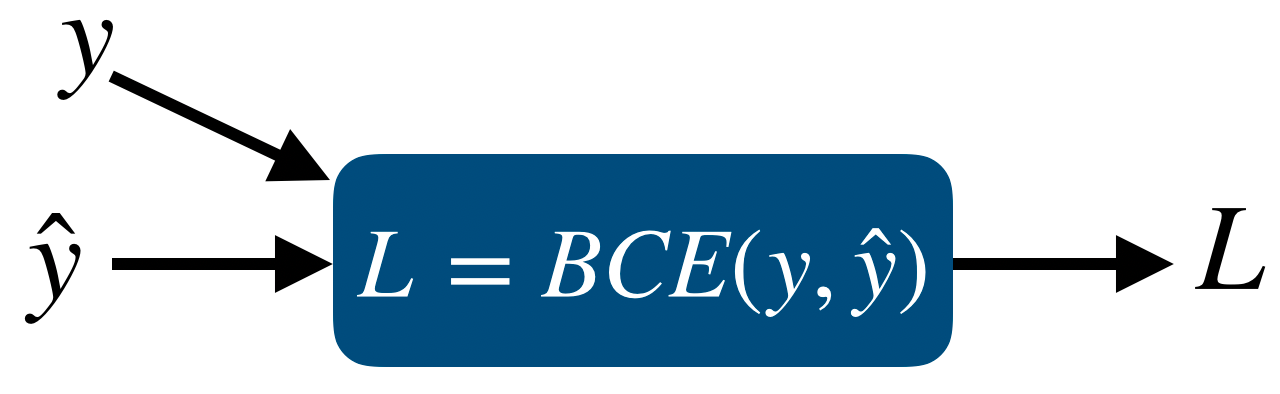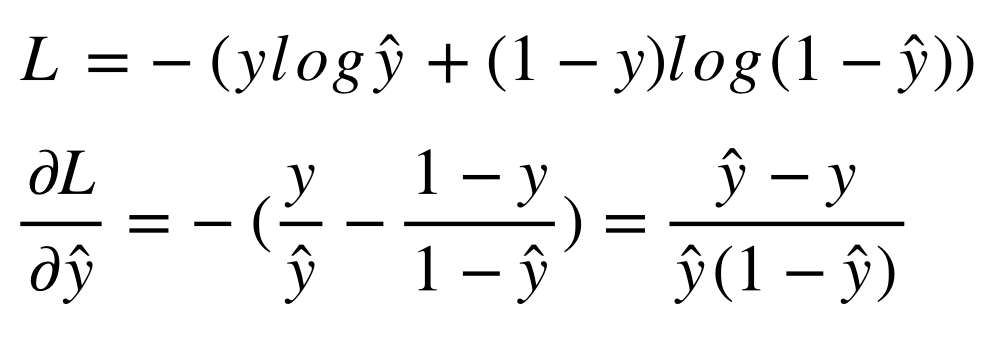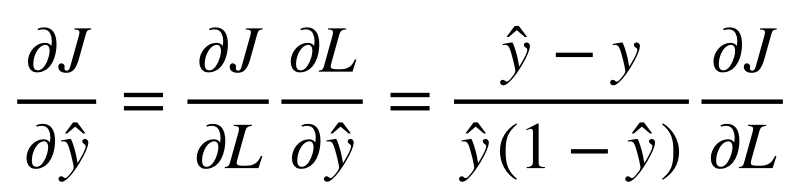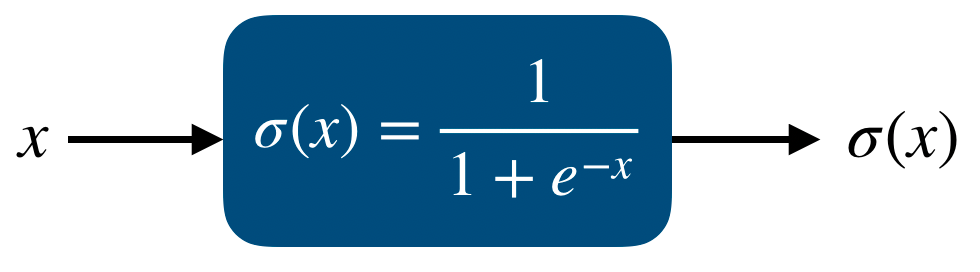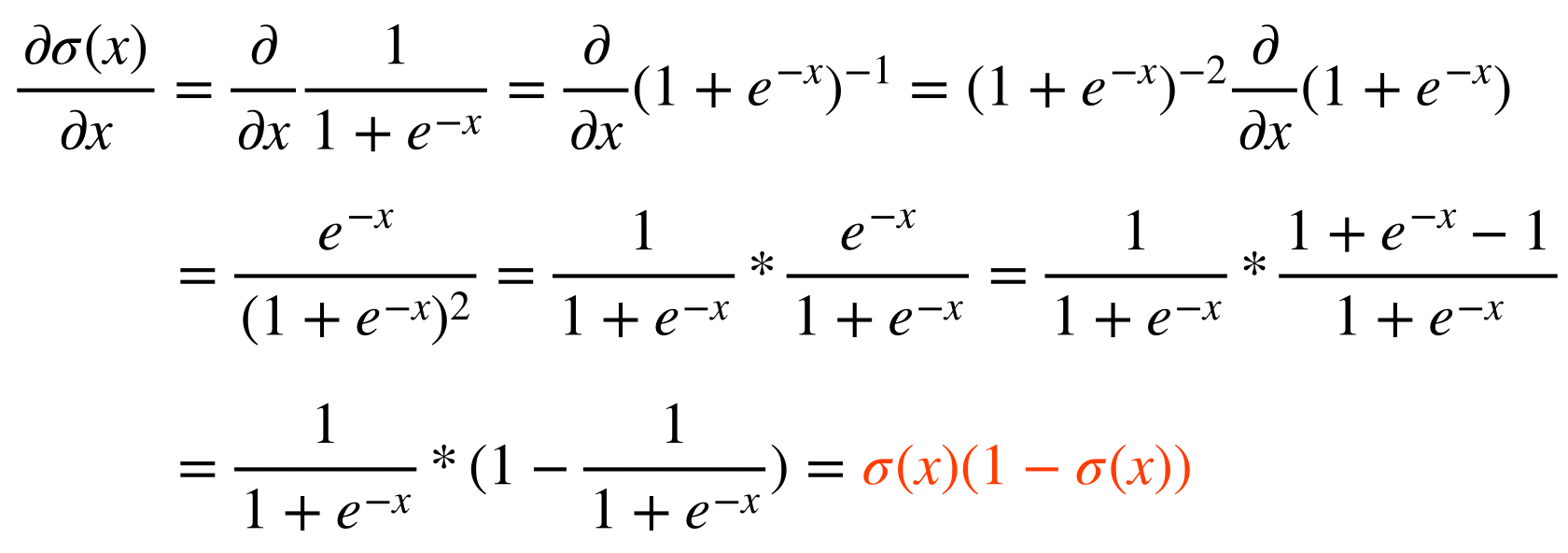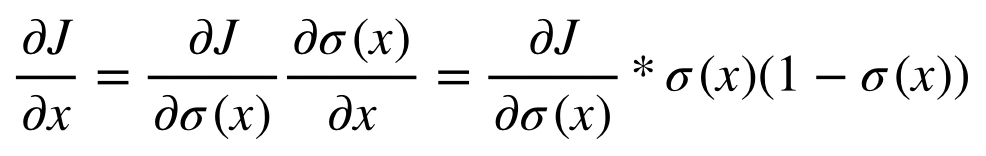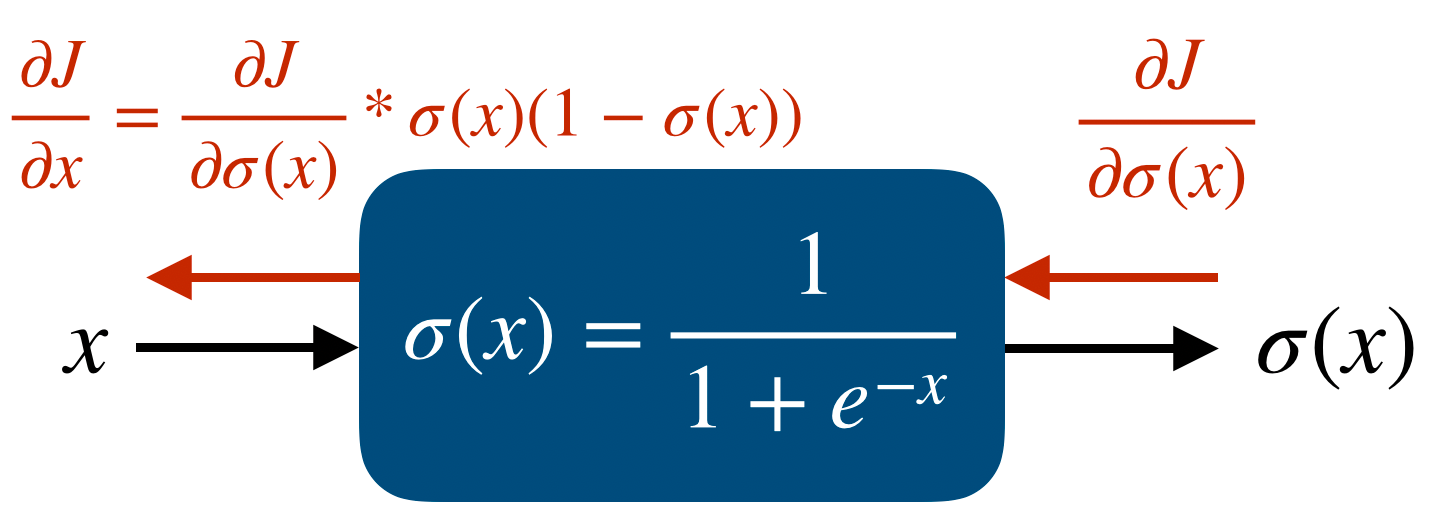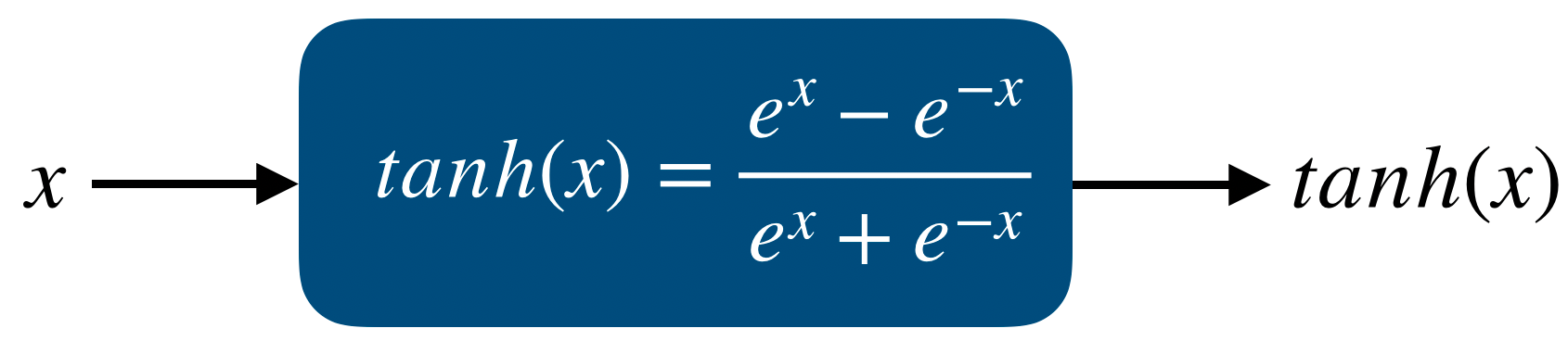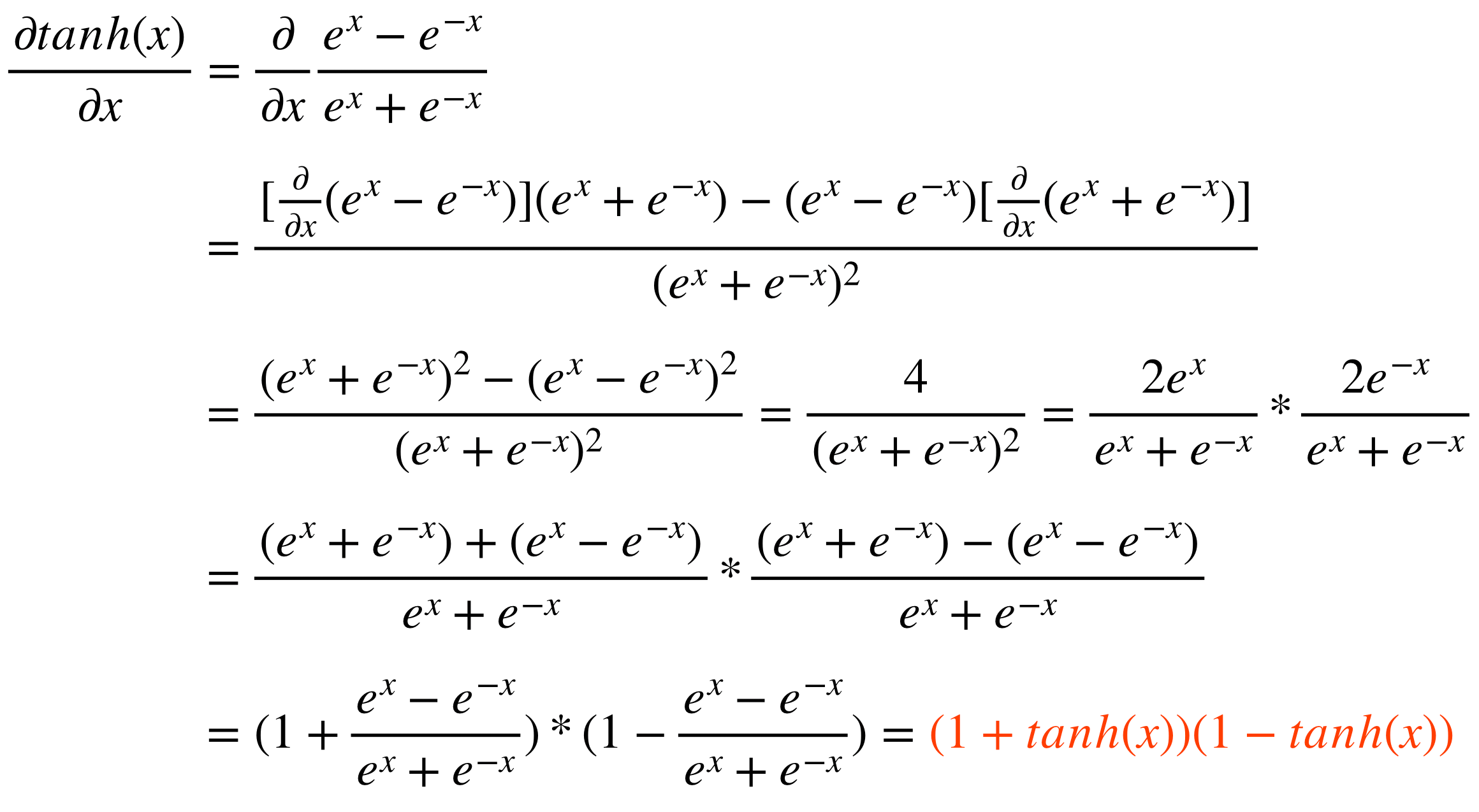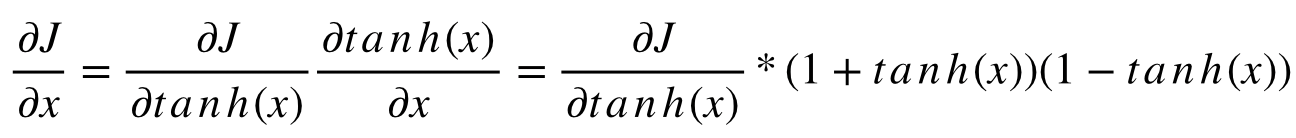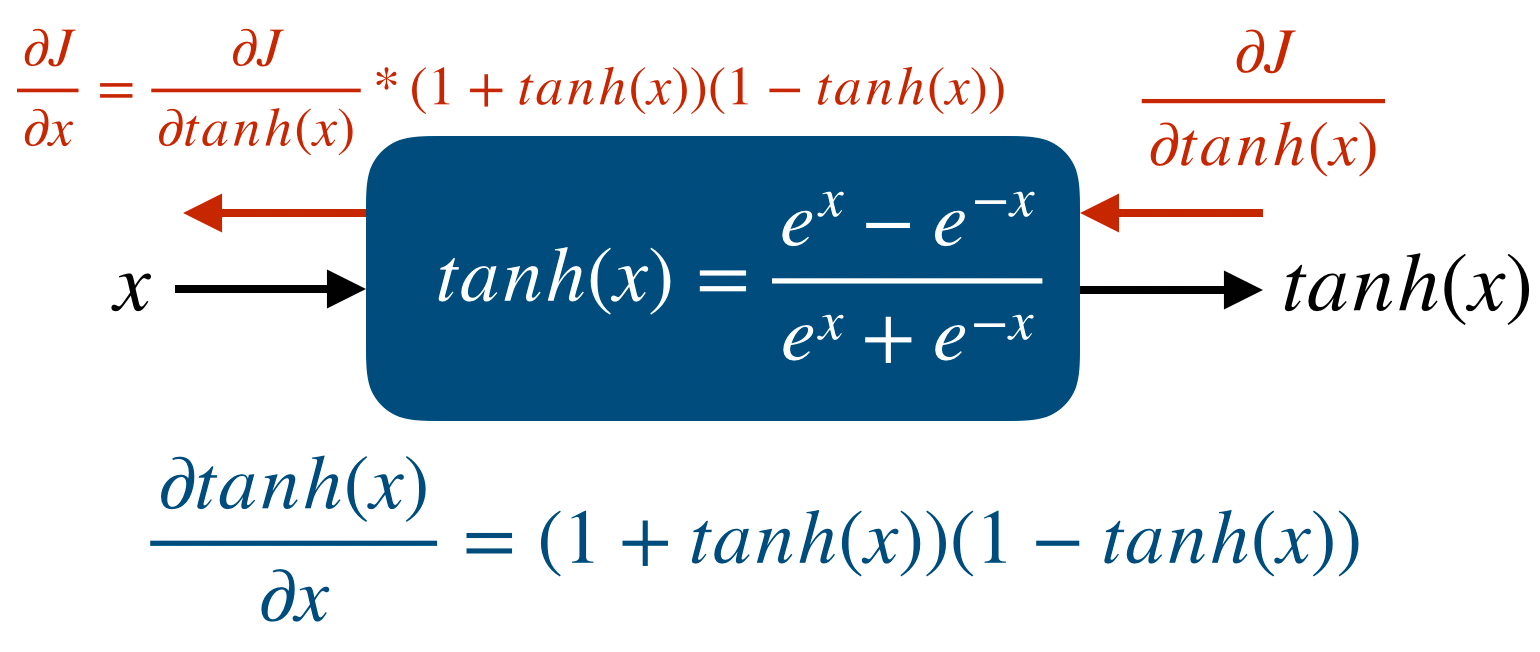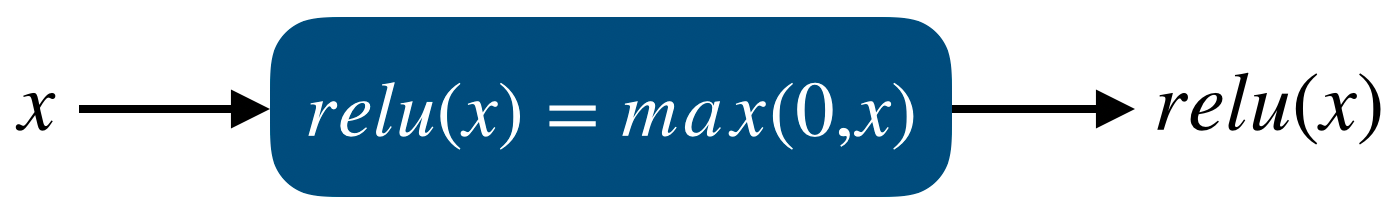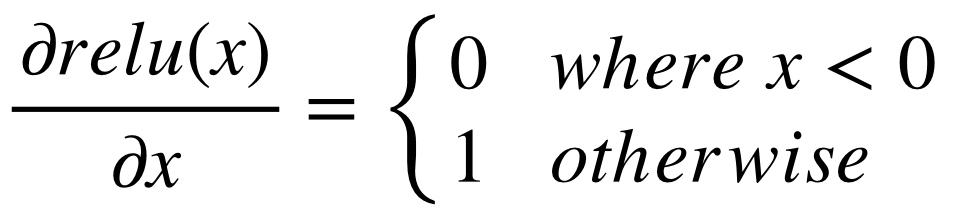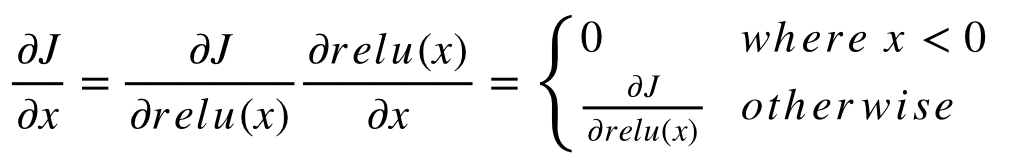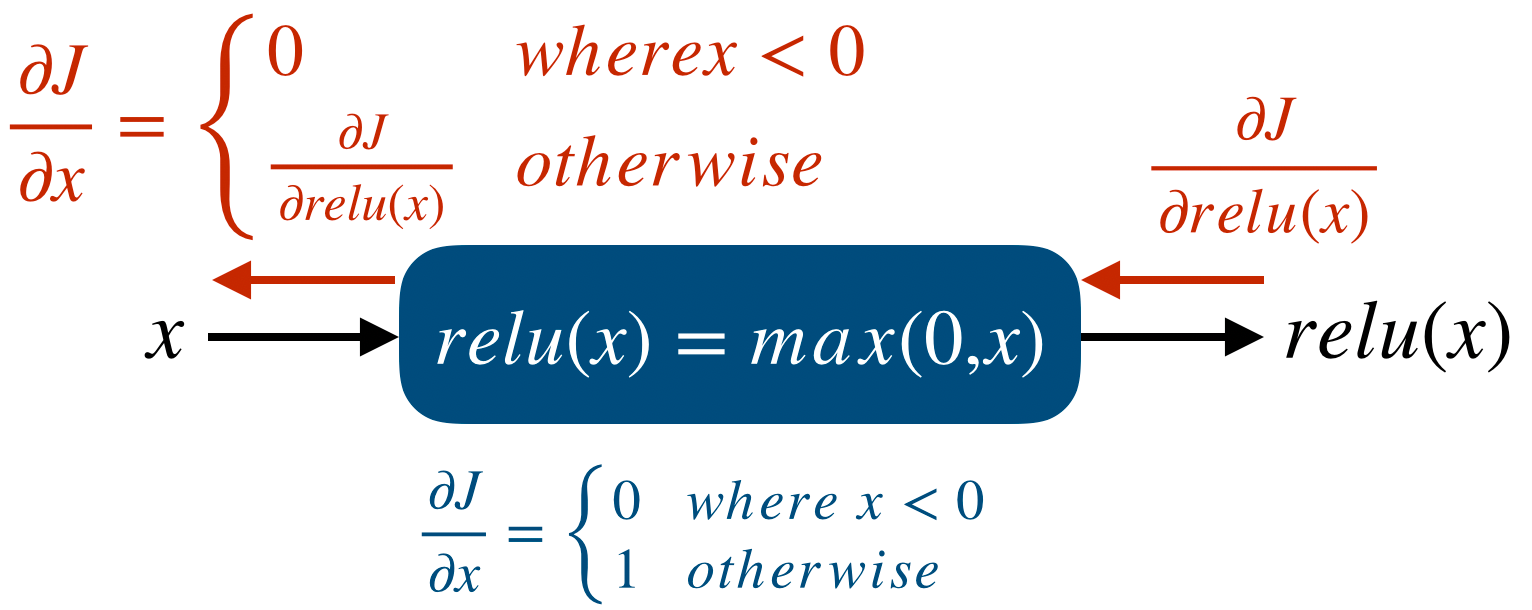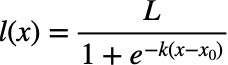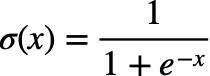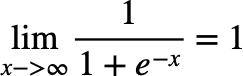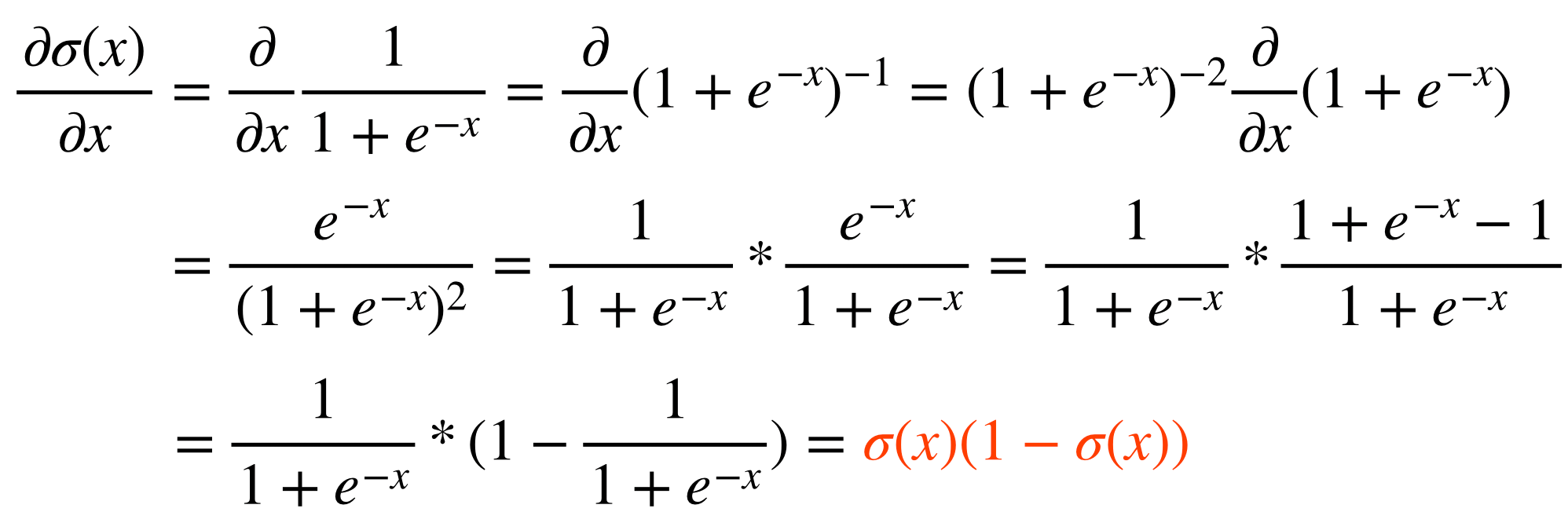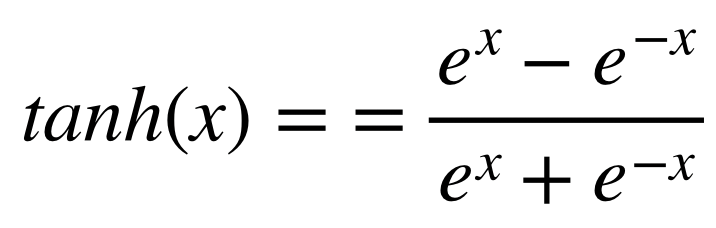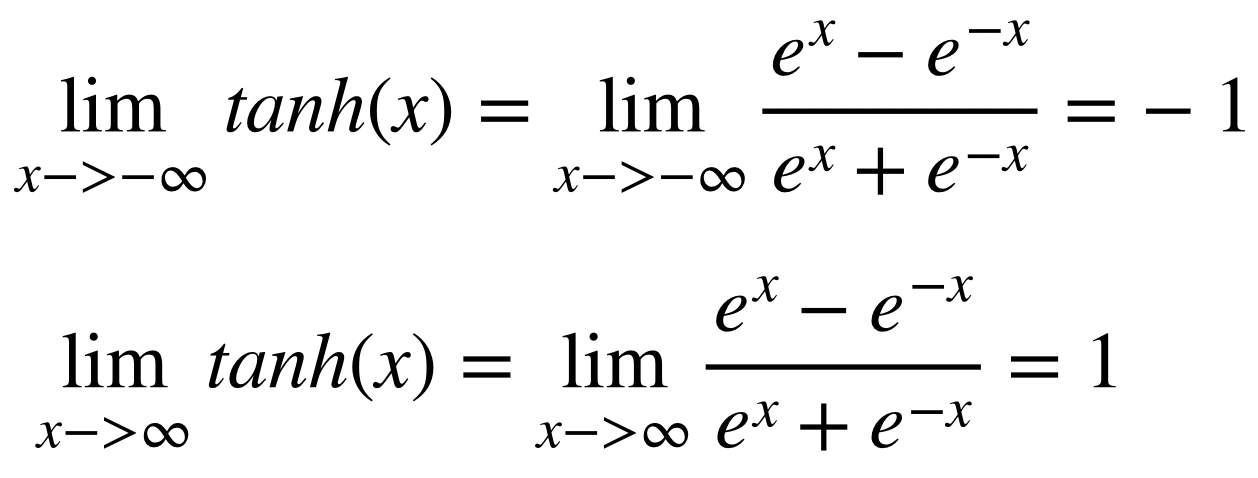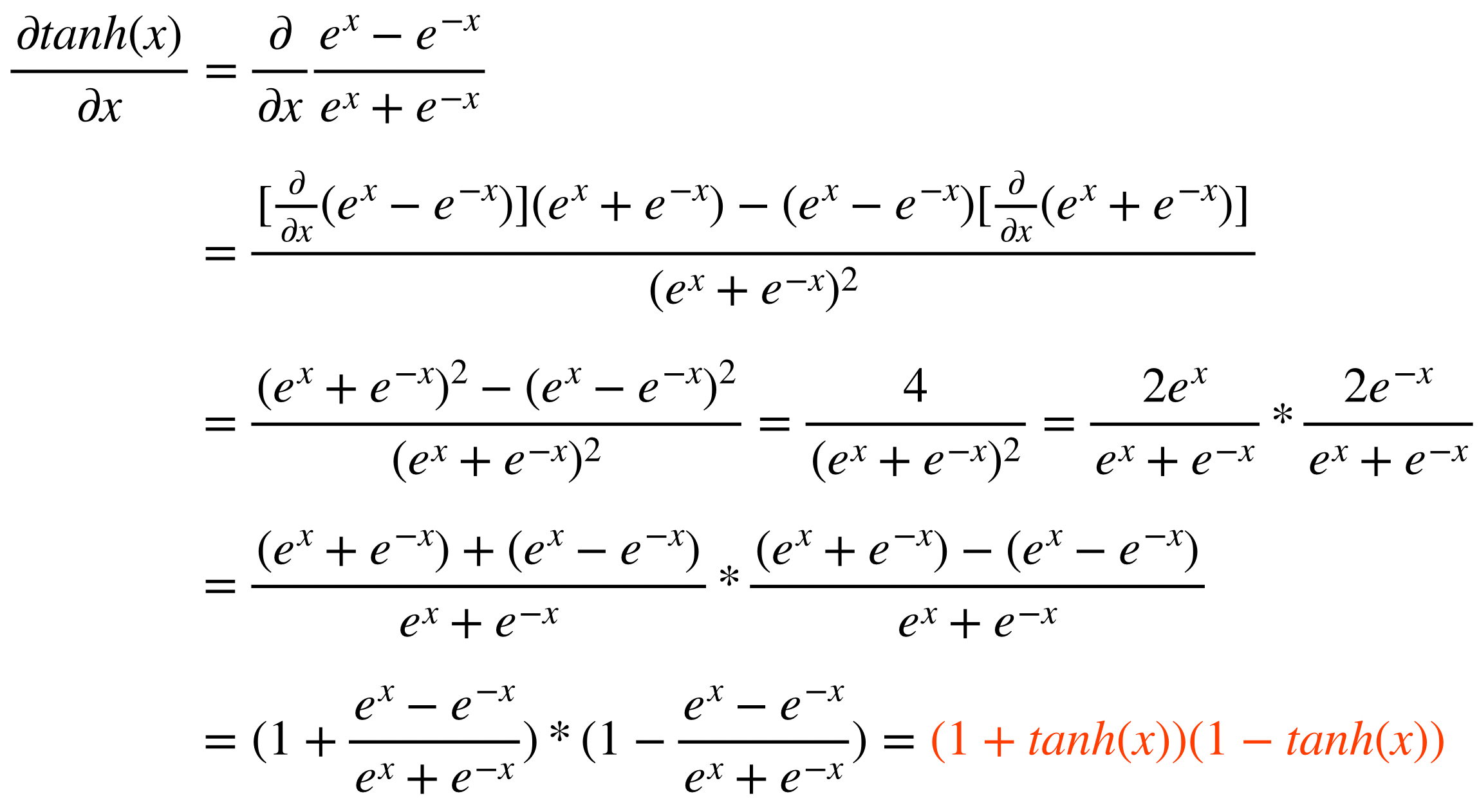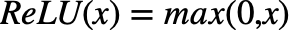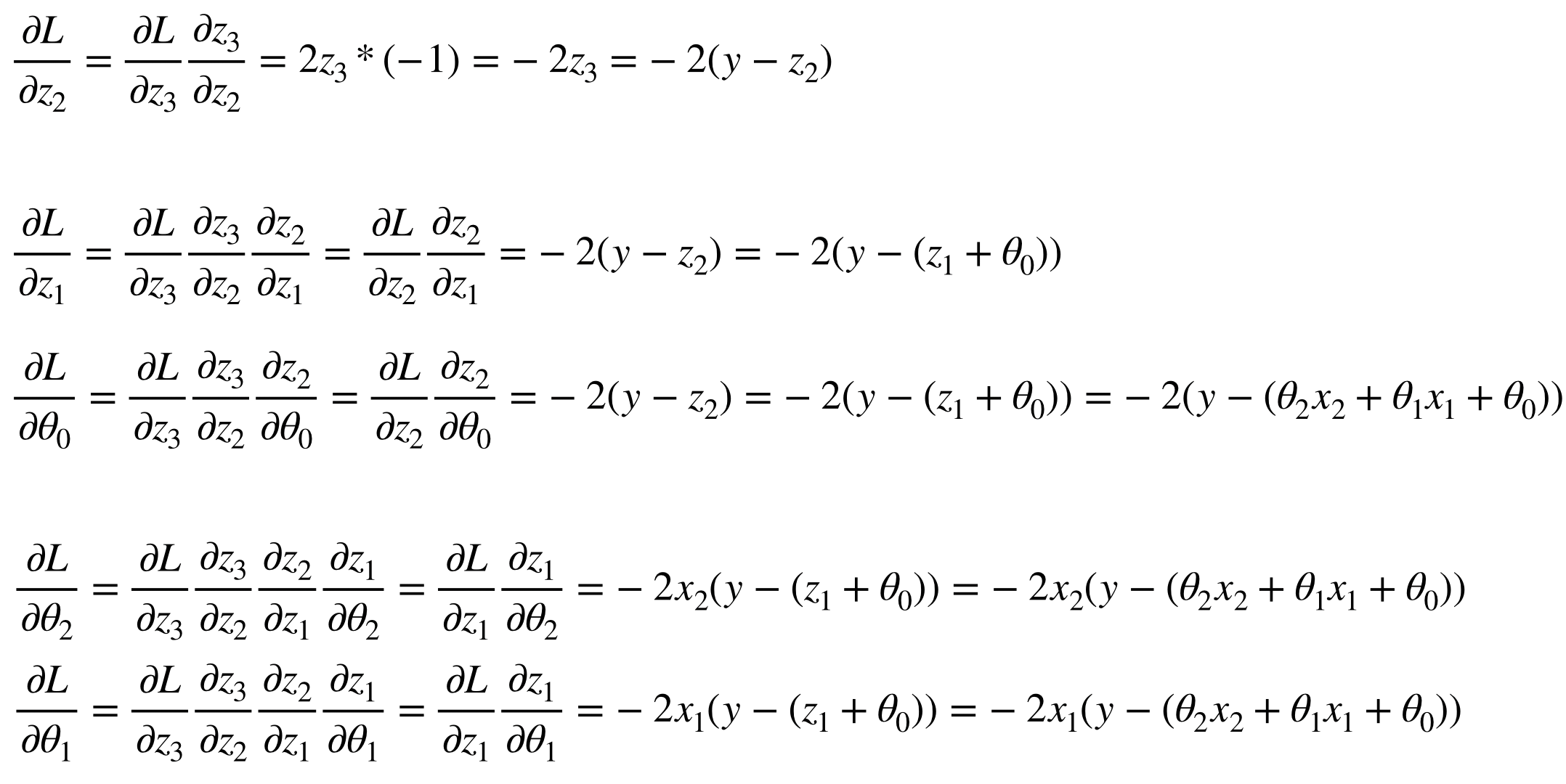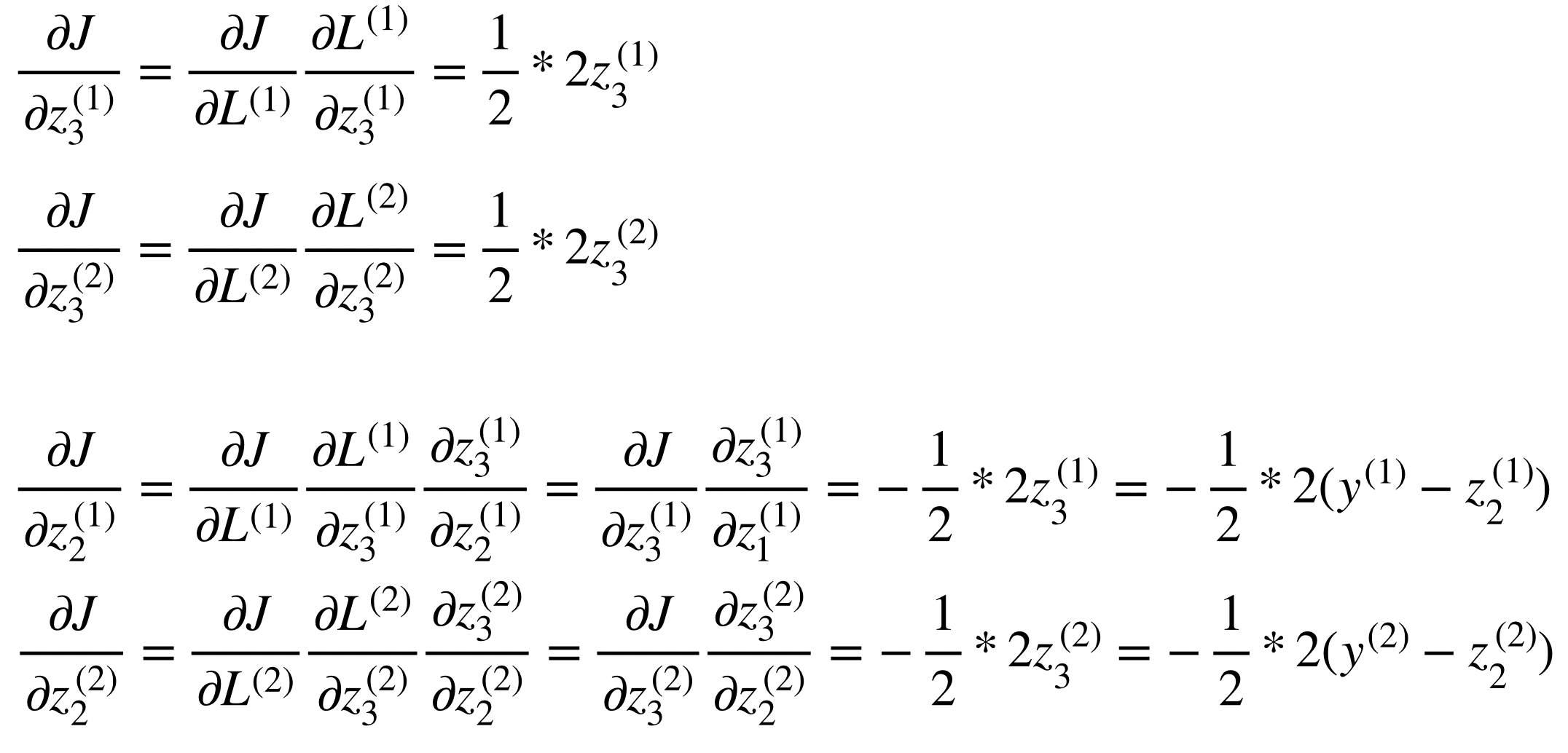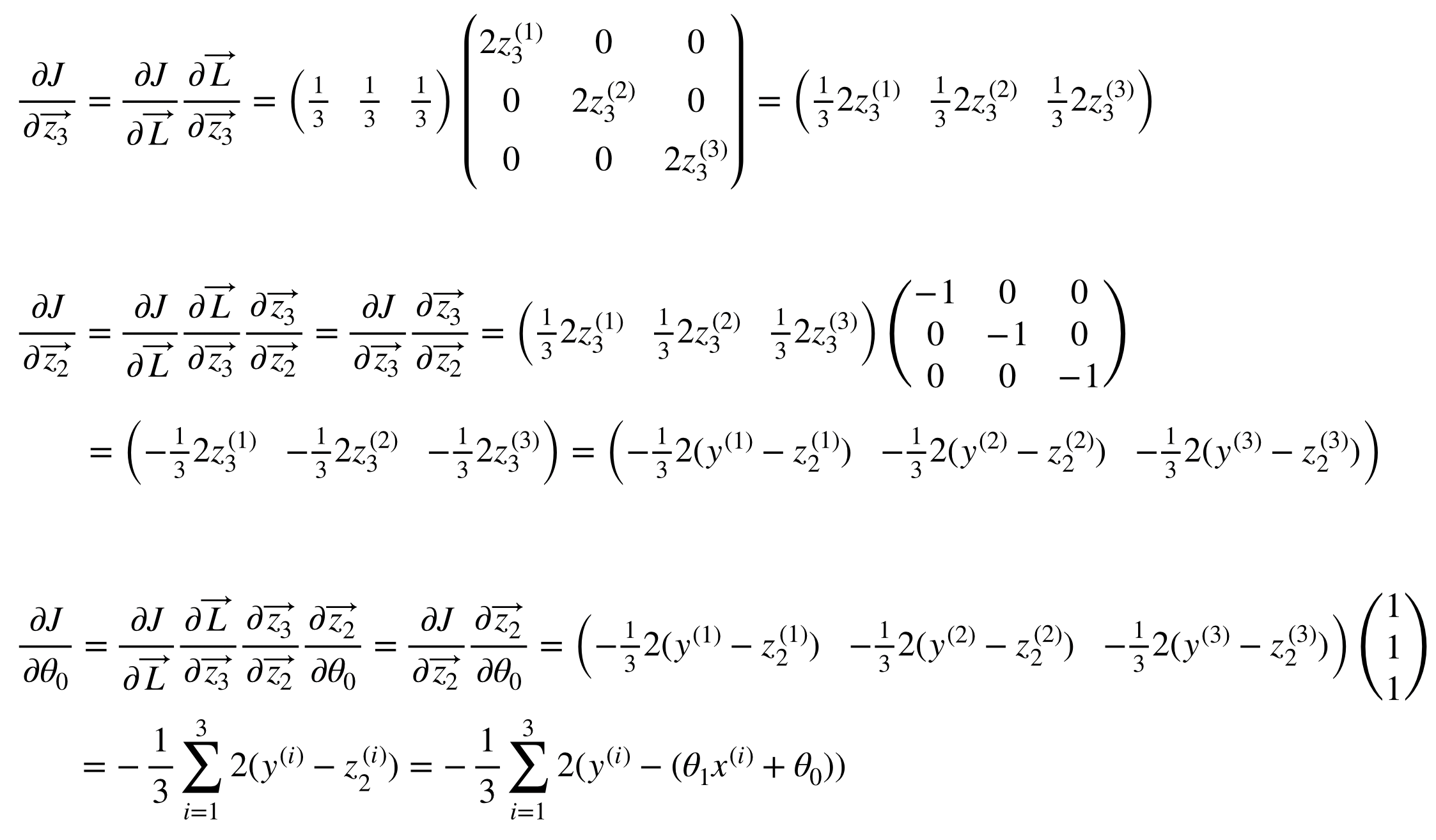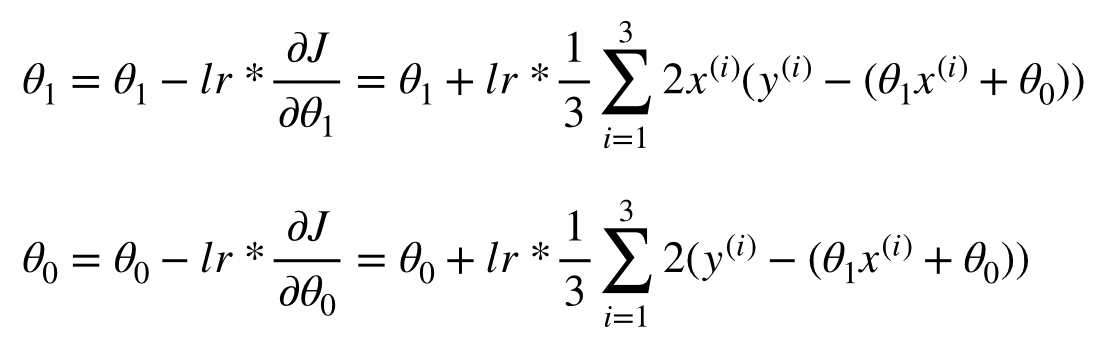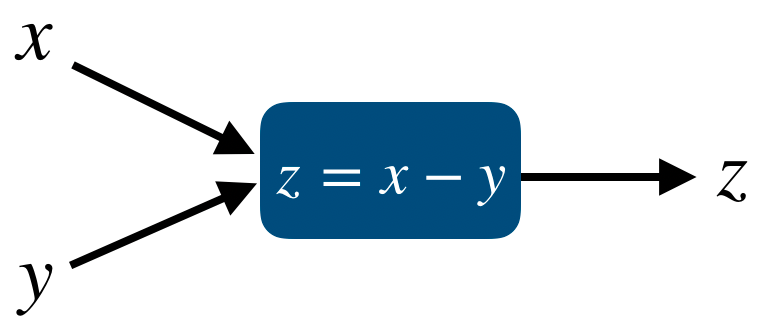이번 포스트에서는 Deep Learning에서 가장 많이 사용되는 activation function들인 sigmoid, tanh, ReLU에 대해서 알아본다.
실제로는 상당히 다양한 종류의 activation function들이 존재하고 2017년 Google Brain에서 개발한 Swish activation function 등, 지금도 효유적인 backpropagation을 위한 activation function들이 개발되고 있다.
이때 이 모든 activation function들을 한 번에 다루는 것은 비효율적이기도 하고, 지겨우니까 대표적인 activation function들에 대해 배우고, learning process에 접목시켜본 뒤에 다른 activation function들의 특징을 파악하는 편이 더 좋을 것 같다.
따라서 몇 차례의 포스트를 걸쳐 기본적인 sigmoid, tanh, ReLU에 대해서 배워보도록 하자.
Sigmoid Activation Function
Deep learning을 배우는 사람들은 아마 logistic regression을 배우면서 처음 sigmoid라는 non-linear activation function을 접할 것이다. 그리고 이 sigmoid function은 logistic function의 subset인데 output이 0과 1사이이므로 확률로의 해석이 가능하며 x축으로의 bias가 없어서 learning에 효과적이므로 logistic funciton들 중 가장 많이 사용된다.
먼저 logistic function의 식은 다음과 같다.
이 logistic function에서 input의 boundary를 (0,1)로 맞추고 x축에 대한 bias도 없애면
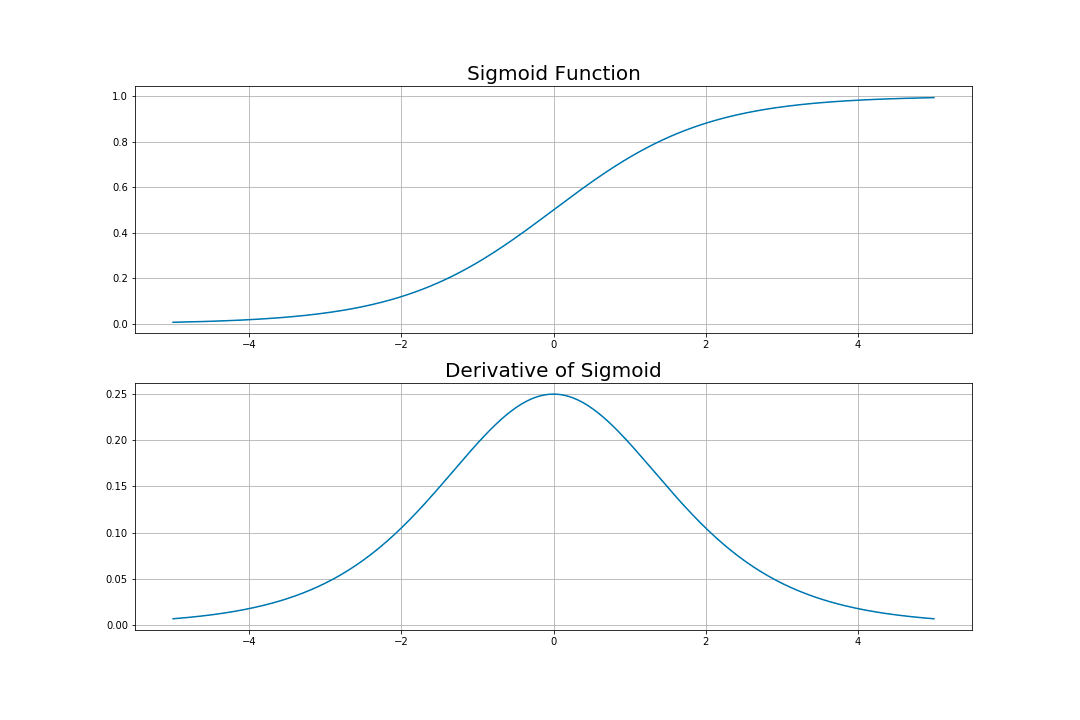
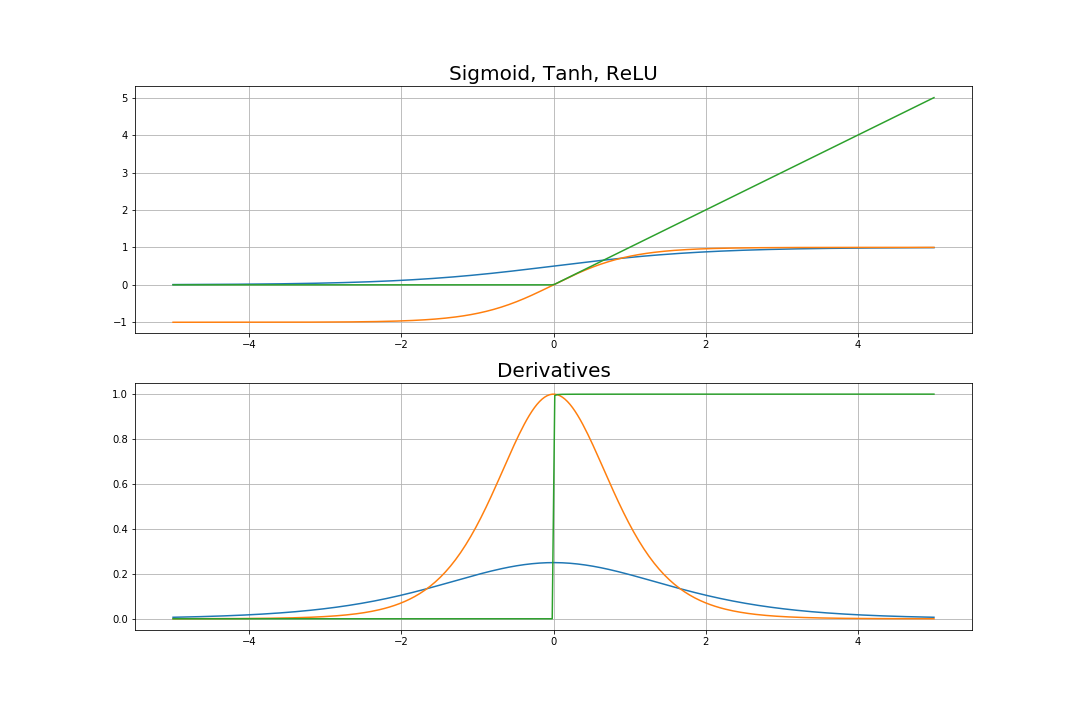
우리가 알고있는 sigmoid function의 형태가 된다. 이 sigmoid function는 함수의 모양과 도함수를 그려보면 다음과 같다.
위의 sigmoid보다 대부분의 경우에서 좋은 성능을 보여주는 activation function은 tanh이다. 따라서 hidden layer에서 sigmoid보다 tanh를 사용하는 경우가 많다. 하지만 마지막 layer에서 classification을 할 때는 tanh보다 sigmoid를 많이 사용한다.
이때 알 수 있는 것은, sigmoid와 달리 activation function의 output이 zero-centered라는 것이다. 즉, deep learning의 hidden layer에 이 tanh를 사용할 경우, 다음 layer의 input이 자동으로 zero-centered input이 되는 것을 알 수 있다. 이것이 tanh가 sigmoid보다 좋은 성능을 보여주는 첫 번째 이유가 된다.
요즘 deep learning에서 가장 첫 번째로 시도되는 activation function은 ReLU일 것이다. 이 ReLU가 다른 activation function보다 좋은 성능을 내는지에 대한 논문도 다양하며 실제로 다양한 neural network에서 좋은 성능을 보여준다. 먼저 ReLU의 식은 다음과 같다.
즉, ReLU의 input이 양수일 경우엔 그 양수값을 내보내고, 음수일 경우 0을 내보낸다. ReLU가 좋은 성능을 내는 첫 번째 이유가 이 식에 있다. Sigmoid, Tanh는 여러 연산들을 하여 activation value를 만드는데 비해, 이 ReLU는 한 번의 비교연산만을 통하여 output을 내기 때문에 연산속도가 빠르다. 보통 tanh보다 5배정도 빠르다고 알려져있다.
이때, 코드를 보면 relu_d를 구현하는데 조금의 트릭이 들어간 것을 알 수 있다. 음수일 때 0, 양수일 때 1을 만들기 위하여 relu에 relu를 나눠주는데 0으로 나눠줄 수 없으므로 gradient에 영향을 주지 않는 0.0001 정도를 더해서 나눠준 것을 알 수 있다.
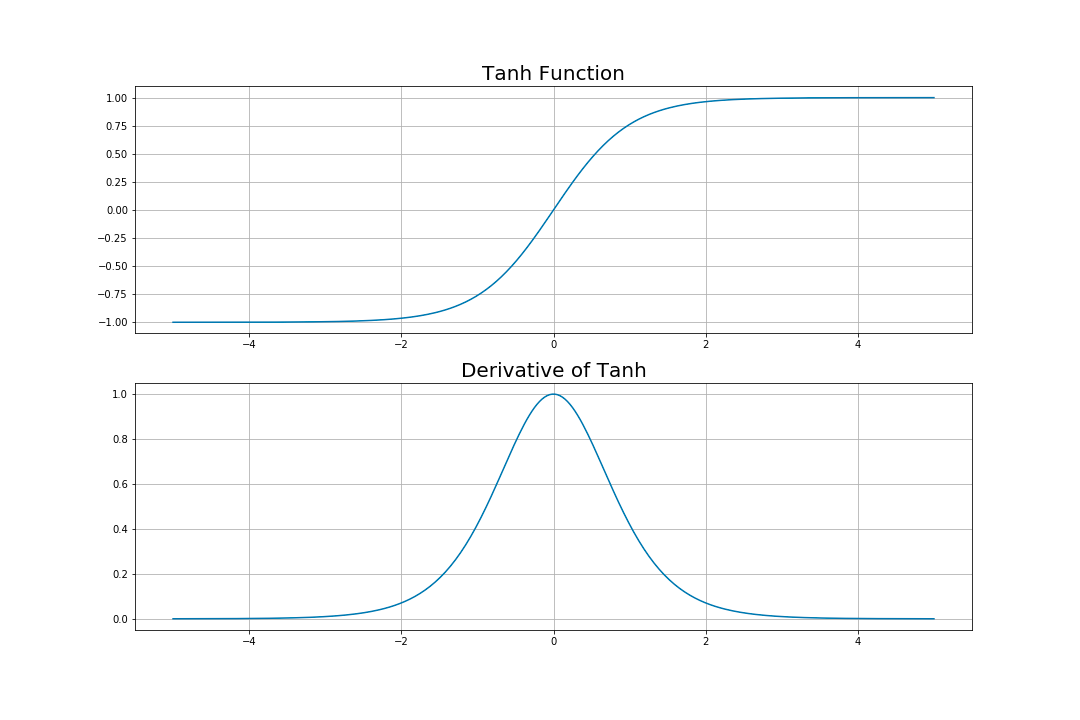
먼저 위의 그래프를 통해 알 수 있는 것은, sigmoid와 tanh는 output의 범위가 정해져있지만 ReLU는 output의 범위가 정해져있지 않다는 것이다.
그리고 도함수에서 sigmoid와 tanh는 1보다 작기 때문에 layer가 많아질수록 propagate되는 값들이 0에 가까워질 것을 알 수 있다. 즉, sigmoid와 tanh는 태생적으로 vanishing gradient problem을 야기할 수 있는 activation function들이다.
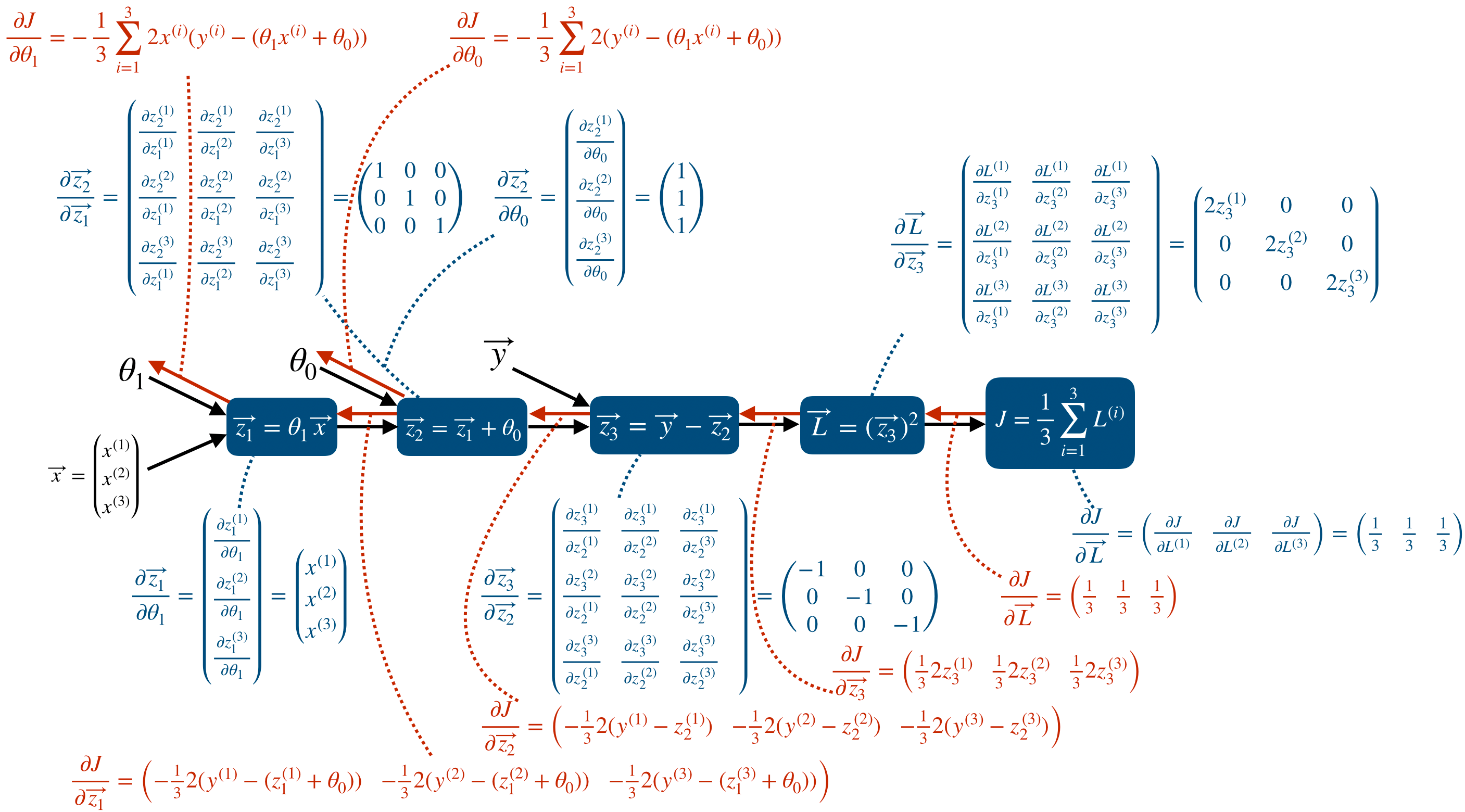
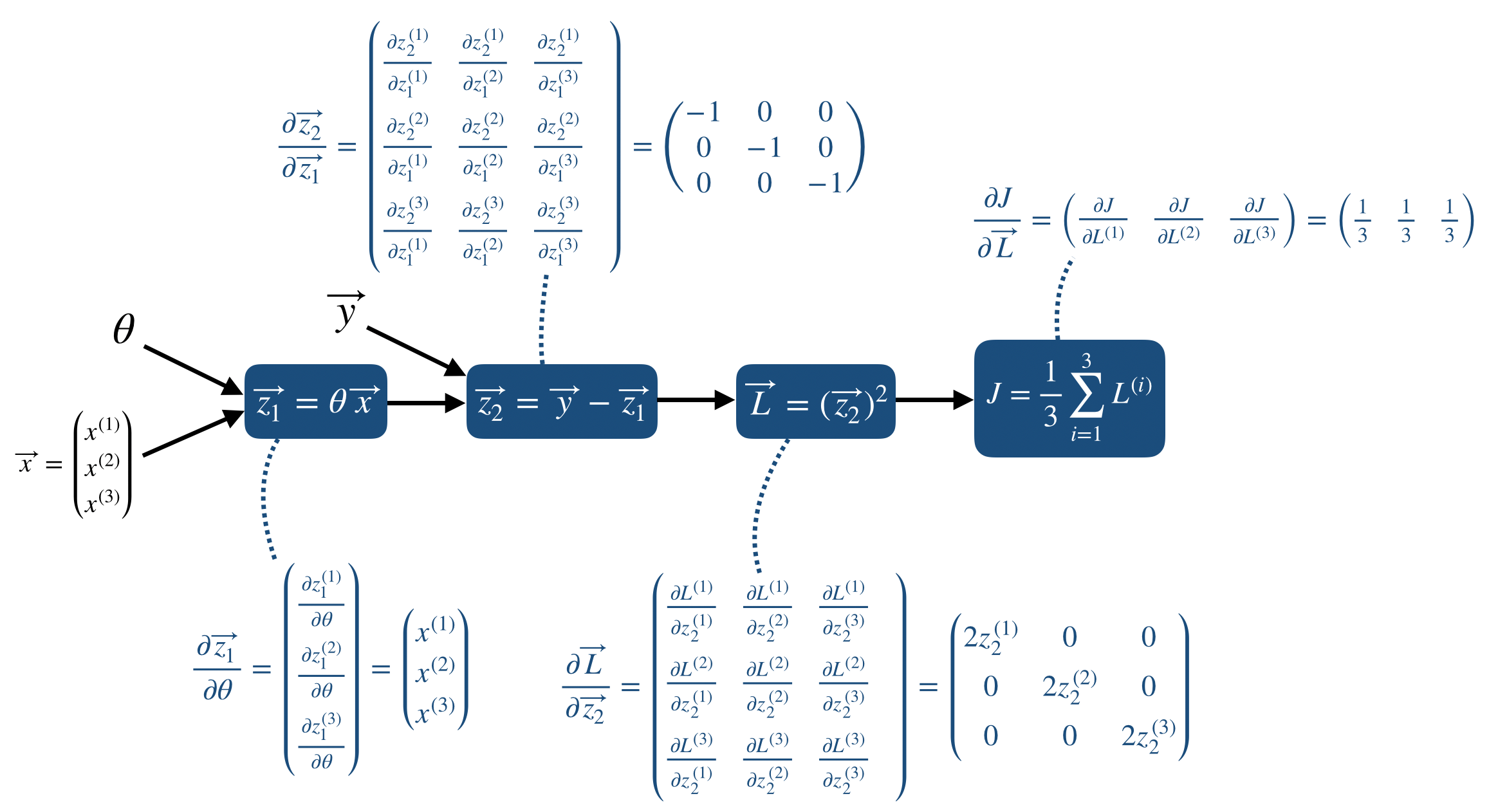
위의 두 번째 단계는 실제 프로그래밍을 하기에도 힘들고, 같은 연산이 반복될 때 사용되는 vectorization을 이용하지 못한 모양이다. 따라서 mini-batch 사이즈가 임의의 n개일 때는 vectorization form을 이용하게 되고, 이 포스트에서는 3개의 mini-batch에 대한 backpropagation을 다룬다.
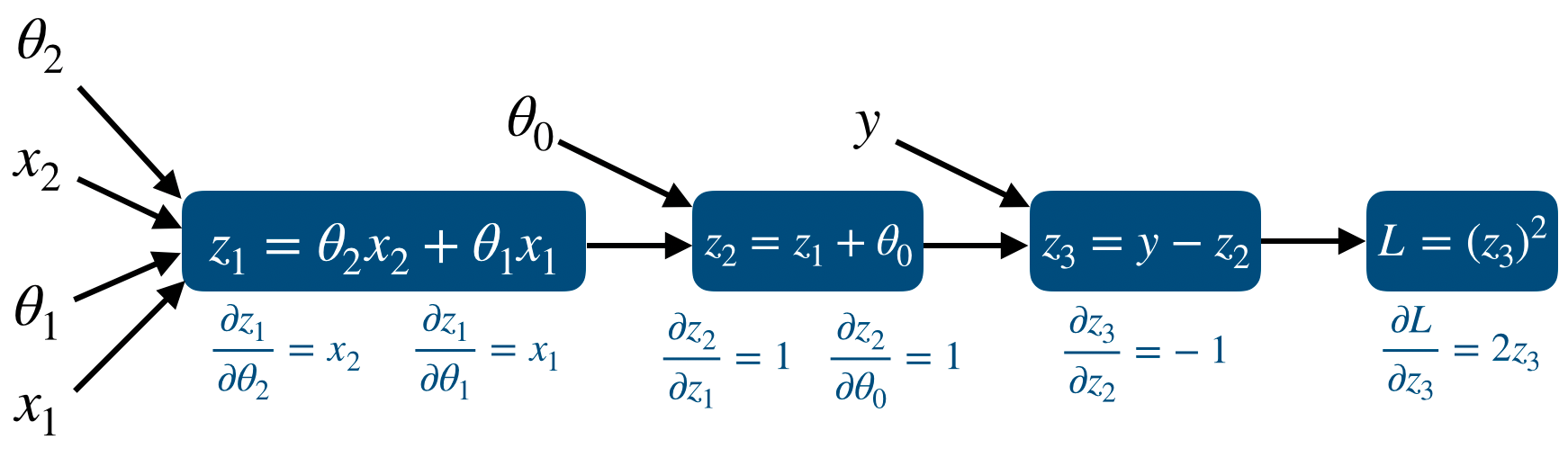
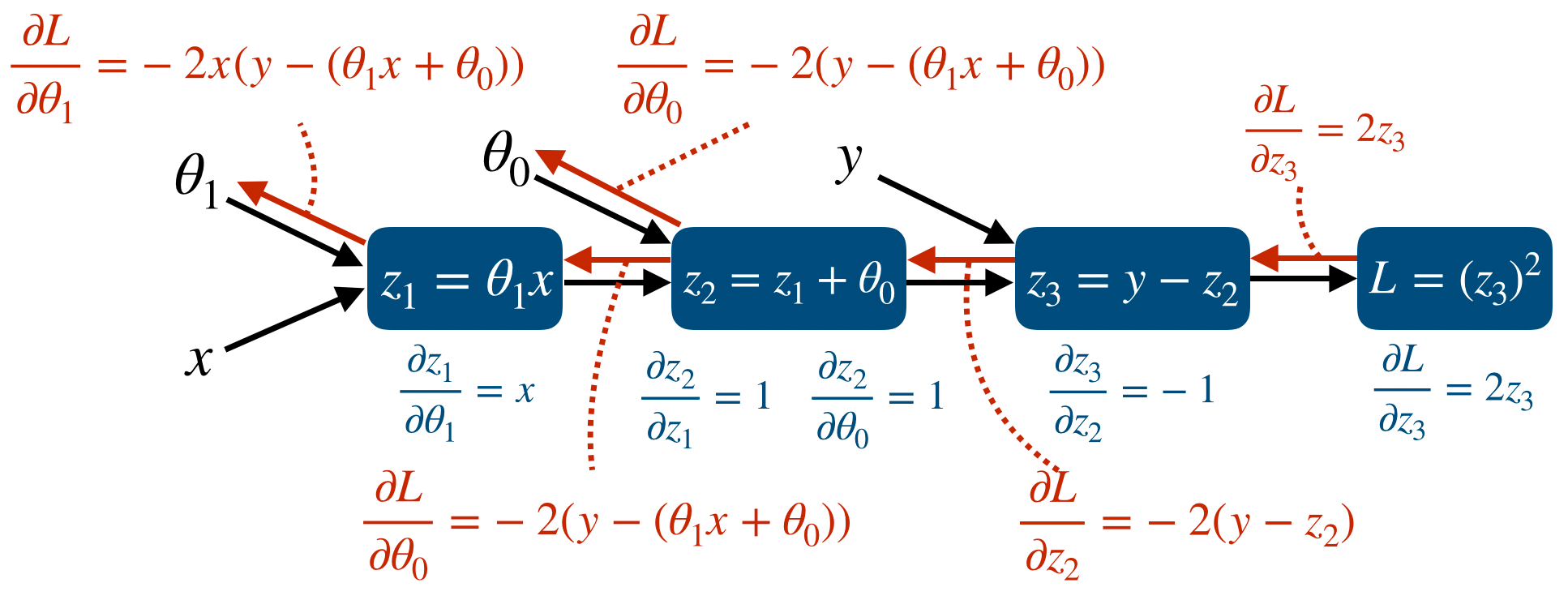
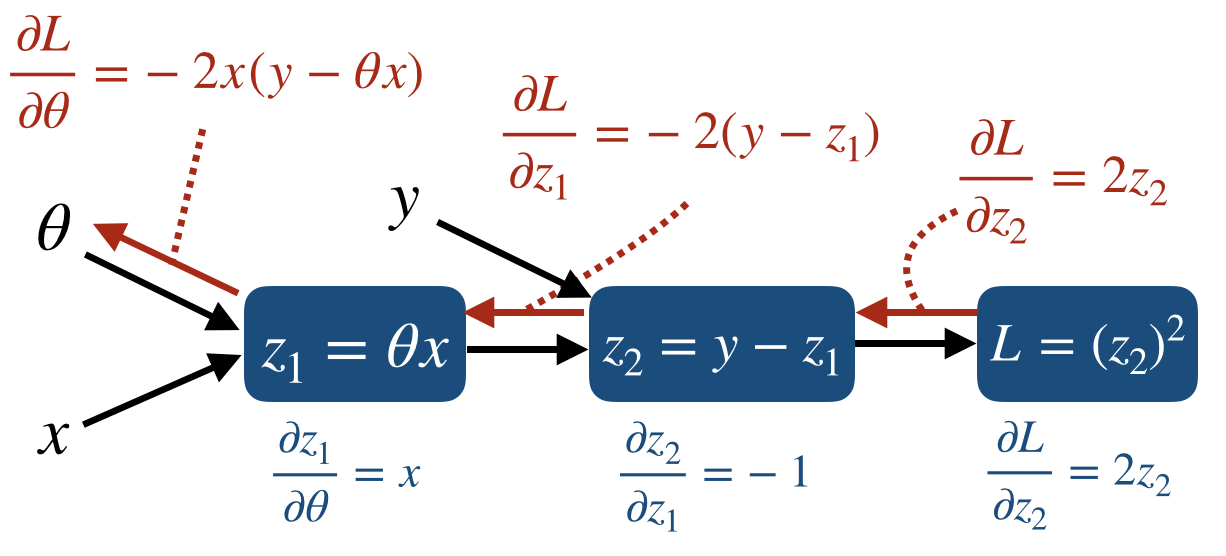
먼저 forward propgation을 포함한 model은 다음과 같다.
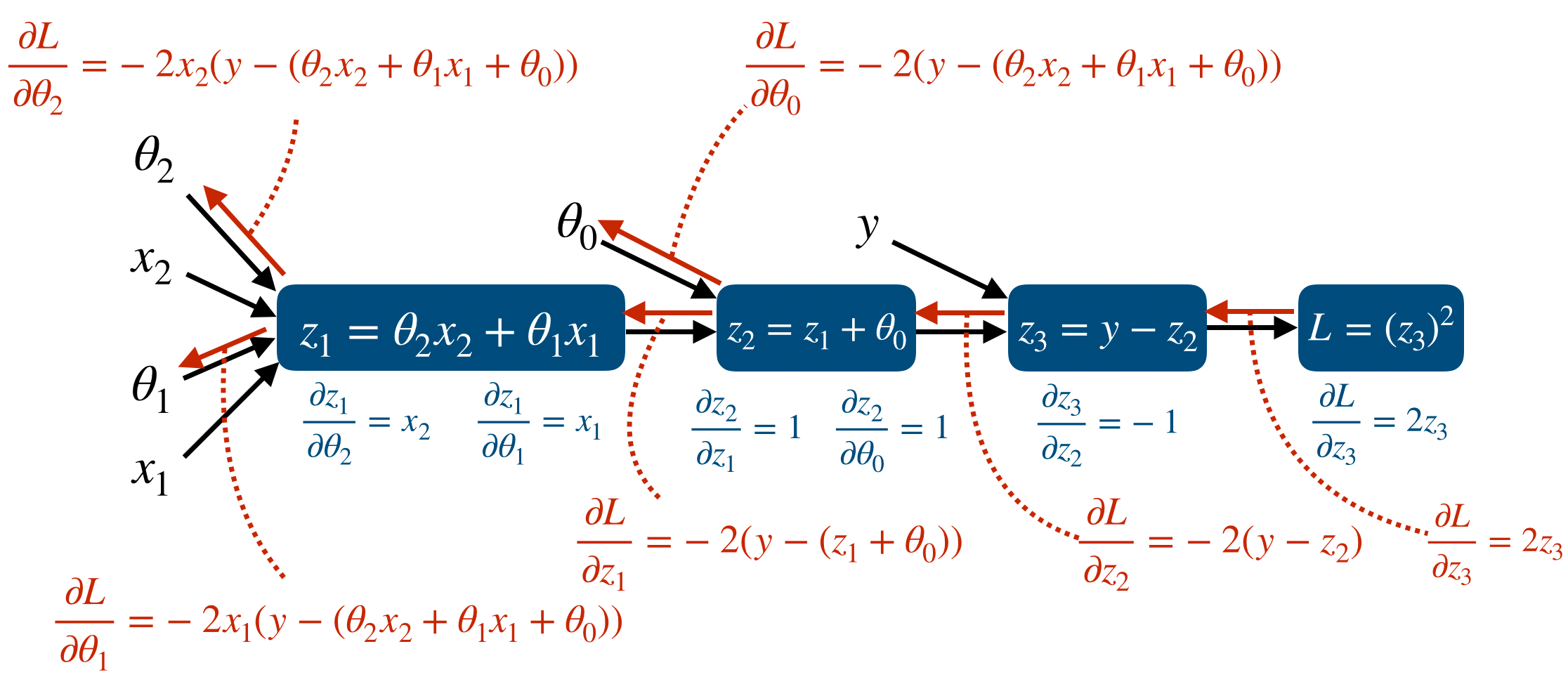
그리고 각 node에서 Jacobian을 이용한 partial derivative를 표시하면 다음과 같다.